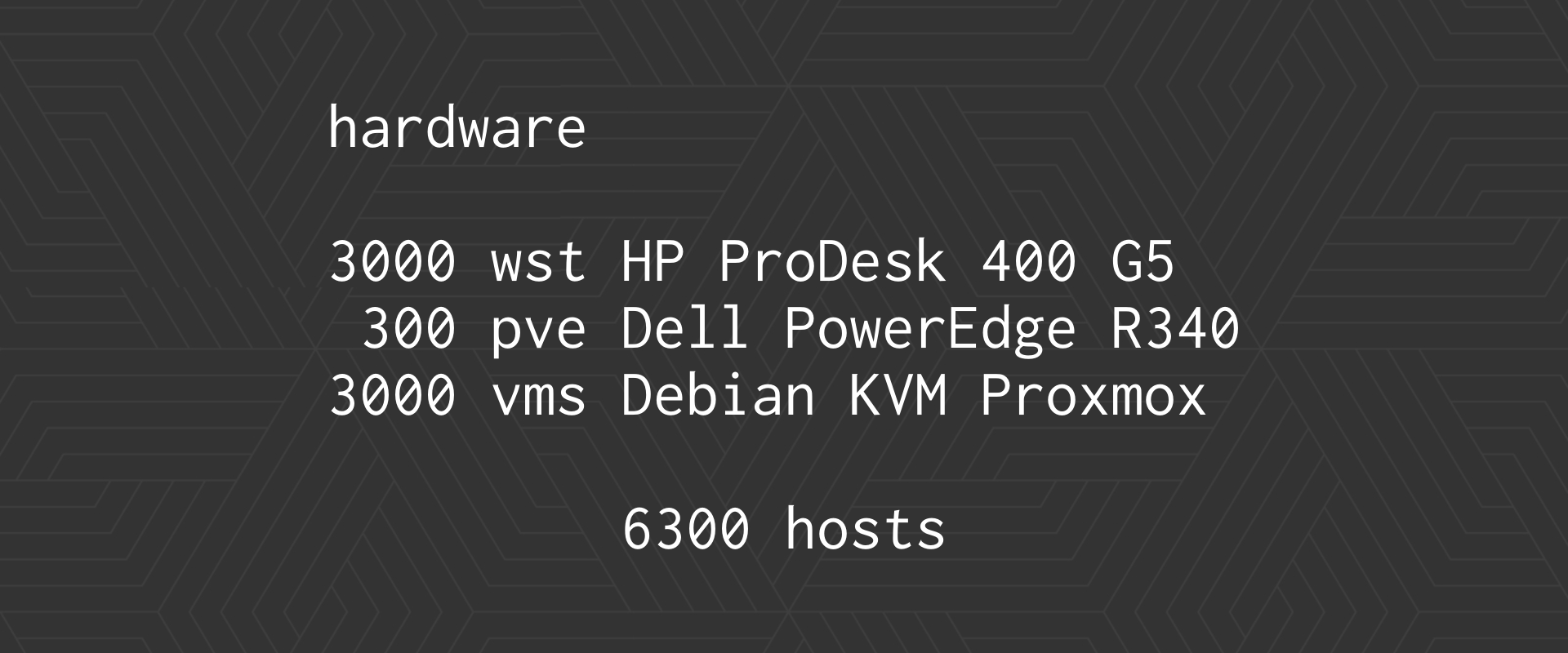
How to migrate 6300 hosts to GNU/Linux using Ansible and AWX
index | about | archive | charlas | docs | links
dot |
git |
img |
plt |
tty |
uml
This post is a translation of the transcript of the talk “Cómo migrar 6300 equipos a GNU/Linux usando Ansible y AWX”
nerdearla
4 years in a pomodoro?
Summarizing 4 years of work in 25 minutes is not an easy task, but due to the large number of simultaneous talks there was no other way to summarize, so I divided the talk into 7 stages, coinciding with the 7 colors of cooperativism 🌈
To detail and extend the talk a little more, I unrecorded the audio and I will be adding references to each topic and/or technology mentioned, for those who want to go a little deeper.
Instead of making Slides I created a website 4 with the
help of Hugo Ruscitti 5 who built the multiple video
viewer 6, which I used to display several videos at
the same time.
Since several people asked about the tool I used to make the graphs, I
put together a post 7 detailing how I generated the
graphs and the timeline 8 using GraphViz
Opening of Guido Vilariño
Well, welcome back to the Infra track on Nerdearla!
All good? How are they doing? Hey there goes that audience still!
Well very well, thank you very much for being here!
I have already said several times, I will say it again the ninth edition of Nerdearla 2022, the 10 years of SysArmy 9 and here we are, here Trac Infra, we have a Trac Dev Online and a Trac Sec Online and the DataScience Trac there in the other auditorium, here in the Konex Cultural City from October 19 to 22, nothing come, you still have time to come, this afternoon, Friday and Saturday if you are watching us online but if you are here, you are already enjoying all the activities that we have in the stands, in the auditoriums, in places to do coworking, games, etc. there is everything thanks! Thank you for being here and joining us!
Presentation
And now the last round of talks is coming, it’s not the last talk, the last round, there are several talks ahead of us.
Well, now we are going to talk about something that I really like, which is Free Software. Who likes Free Software here?
Let’s go still! Look, you have FANs ! Jewel
Well then, we are going to welcome OSiRiS GóMeZ, which is a partner of
gcoop 10, which is a Free Software Cooperative …
Heroes without capes, as we usually say...
He is a GNU/Linux programmer and Administrator (you saw that I said GNU and not G-N-U, but Richard Stallman 11 gets angry) he is self-taught and a fan of automating everything from a terminal (from tty actually says here) and is very interested in disseminating the use of the Free Software, so…
I leave you with OSiRiS a round of applause please!
Intro
Wow, I’m so tall! Can you hear it? Yes? Perfect!
(well, it seems to me that it sounds better there)
First I apologize if I cough out there because I have a bad throat.
And what I’m going to try to do in 25 minutes, if I can do it, is tell
you the story of gcoop and Banco Credicoop 12 in the last 4
years.
Basically it is a migration project of the entire Infrastructure of the
Subsidiaries, there are many, throughout the country and well, it was
quite a challenge, we did it!
But we are going to see it step by step a little as we were living it.
lab laboratory

Initially we had a laboratory stage, in this laboratory stage we had to analyze if it was possible to do this migration project and with what free tools was it possible to do it?
Basically what we detected is that first we were going to use Ansible because we had already been using it in gcoop and we were very happy with the use of Ansible, eh, basically it was to make roles and playbooks, this code that we wrote was going to be in a GitLab repository and this GitLab repository was going to be obtained as Infrastructure as Code from the AWX tool to make the deployment or the deploy in all the necessary computers and something…
(let’s see if this works for me…, yes, no, there)
The little bar below (let’s try to make it stand still for a minute) is a timeline of all the projects that we ended up using eventually at some point in the project, I’m talking almost 4 years and the interesting thing is that the first The day we started this, which was in 2018, we had no idea that we were going to be using that bar, that is to say, that there are a lot of projects from different Free Software development communities around the world that were doing projects that later we We were going to end up using them and this is the important thing about Free Software, that is, we empower each and every one of us, this… Building and finally giving back something else!
Having Ansible and having AWX with GitLab we could already start to do a massive deployment, but the first obstacle we found was that we had to replace a workstation, the workstation that the Bank had at that time was an Operating System that had 2000 on his behalf and it was 2018 so he was a couple of years out of date!
(can’t hear? ah well that’s ok sorry, I thought you couldn’t hear)
And one requirement we had was that these workstations needed to connect to users that were in an AD (Active Directory), so that AD was in Headquarters and the workstations were scattered…
(can you hear? There?)
… In different cities, throughout the country…
(I don’t know if I’m coming, is it very loud? Is it okay? Well, yes…yes, no…no, yes…yes, no…no)
Well finally we were like this, we had a workstation based on Debian, it was clear that we were going to use that and we had the AD, so we had to find something that, a piece that joins this in the middle and this is called IPA, it is a free development that can be used to integrate.
(Me? I grab… Sorry… I have 2 hands, I hadn’t realized!)
Well… So we managed to get users to talk to the AD, this, through IPA and finally the other leg that we needed was the server part, in each branch of the Bank there was a server, instead of ending with a 2000, it ended with a 4 (the Software) and also in 2018 imagine!
And via a VPN we were going to get to the server, the server was going to be based on Debian, a distribution called Proxmox, it was going to virtualize and it was going to have a lot of virtual machines with Debian again to complete the scheme that was the stage of Laboratory, it took us six months to realize that!
dev develop

And we went to a stage of Development!
(Let’s see if this works? A little there, we’re better)
In the development stage we already figured out how to deploy these services and this service deployment is basically the AWX connects to GitLab, obtains the code, with that code it communicates with the iDRAC which is the administration interface of a DELL server and It deals with creating the storage, this, configuring the BIOS and restarting the computer.
As soon as you restart the computer, Proxmox starts running:
- talk to the NodeVPN, get an IP
- talk to a PXE server, get an image with a Kernel
- boot, get a base image
- goes to a local CDN, looks for local resources,
- what it does not have locally goes to Headquarters (when I say Headquarters is because we can be in any Subsidiary, anywhere in the country)
- and finally if Debian packages are to be installed, we need a APT repository and we have a local cache, but if the package we need is not in the local cache, it will Headquarters accesses another cache repository and finally all the packages are installed
- and in this way we have a server, this… from scratch, recently installed!
Now, thinking of… More… To see him…
(let’s see if it’s possible, here we have…)
There is the start of the iDRAC interface, in the background what you see in green and black is me playing to get debug, but the process is automated, that is:
- from AWX the connection was triggered
- the server is brought up the server takes an interface by PXE
- you’re going to get a Debian image that’s going to be self-installing, it’s a process that lasts a series of minutes
- and the operator that triggers execution from the interface AWX administration, you don’t have to do anything but wait!
And in fact at the time of generation of servers, imagine there are 300 subsidiaries, they had to generate 300 servers, they generated 3 servers at the same time, in this way they generated it in parallel at Headquarters, this simply by opening the box connecting 2 network cables and from AWX triggering the execution and waiting, I don’t know, I think maximum 1 hour and you had 3 servers installed and configured from scratch, with all the components they had inside, that is:
First a Debian Net Install is done which is what we are seeing there in an accelerated way
- Then the computer restarts
- The equipment is registered only to the AWX, in the inventory, it says… I am such MAC, I am such IP, I am such equipment
- and from there the operator can fire the second execution that is… Well now you stop being a base Debian and become a Proxmox
- and after you have already become a Proxmox, it goes on to… A circuit that what it does is create the 10 virtual ones that are needed and
- and then a third circuit that what it does is create the services that is inside each virtual and the whole process is automated
- and finally… Nothing, a server is running that will have all the virtual ones you need!
But it will also have the ability to generate another server exactly the same, this one with the same steps, that is:
- to generate a server we use a server
- to generate another server we use that same generated server
- recursion they say…
Workstation… Well with workstations it happens to us that as there were many, there were no longer 300, they were 3000, what we did is a base image, that base image was sent to the workstation manufacturer to clone
And what you had to do afterwards was select that workstation and apply the changes to it, whatever is new and basically enroll it in the network.
(here what we are going to see, I am going to see if I can pause a bit…)
Eh… On the right… yes… I’m on a Proxmox server with a virtual one, to play in Development.
And on the left I have the AWX interface and basically what I have is identified in the inventory the IP of the host, the MAC, the hostname since the Subsidiary it belongs to, in this case it is 661.
And on the right, what I am going to see is that what AWX is going to execute on the left, on the right, it is going to materialize in some way. In this case, it is a fairly simple example, which is to change the wallpaper, but what is interesting is that it is done from Headquarters, the workstation can be anywhere in the country.
And the operator only sees the AWX interface, he never sees the workstation screen, he simply chooses a series of templates and within the template what he chooses is the limit.
The limit is basically one or more teams together that will deploy, they are always deployed in parallel,
This… All that’s needed is the limit on that and once it’s run in the control panel what you’re going to see is a bunch of messages.
(there you can see half a boy but… Let’s see if I can zoom in… yes… eh)
What is green is fine, what is red is a serious error, this little orange is when something of value changes and cyan when it could be skipped because it was not necessary to do so.
The scheme is quite simple, it is a web page, values are chosen, those values…
(let’s pause there, let’s see…)
There for example we see, we are in a workstation and we see the
variables that are loaded inside the AWX and it says for example the
default_background and the name of the image and basically that value
comes from GitLab and is versioned, but from the Administration panel
of AWX, if you have enough permissions, you can change it and if you
change it, as it is in this case here, eh… It’s trying to change the
background of the screen, let’s see if it succeeds in this execution, I
think there was an error there .
(I don’t even remember what I did…)
Yes, indeed there it says gcoop.jpg and it says failed and if we look
in the log … There it will be going down… Where it is in red is
because it is trying to find an image that does not exist, so now what
it is going to do is… There is no no problem, the operator can change
the file name to the corresponding file name, there he put the correct
name, it tells him to save.
Execute again and it is executed on the failed equipment, which can be 1 or many and once it turns green, that is, the operator only waits for it to turn green, if it turns green everything is fine and continues with another template or with another team and if it turns red, something happened…
And so it immediately changes on the right side, in the job to the user while he was “logged in”, that is, the example is quite simple but it also serves to comment that any task, no matter how small, can be automated and In fact, there are 3,000 workstations, users do not have permission for anything, that is, everything is done from Headquarters in an automated, centralized manner, all changes are versioned, because It’s the only way to keep control over so many computers…
dep deploy
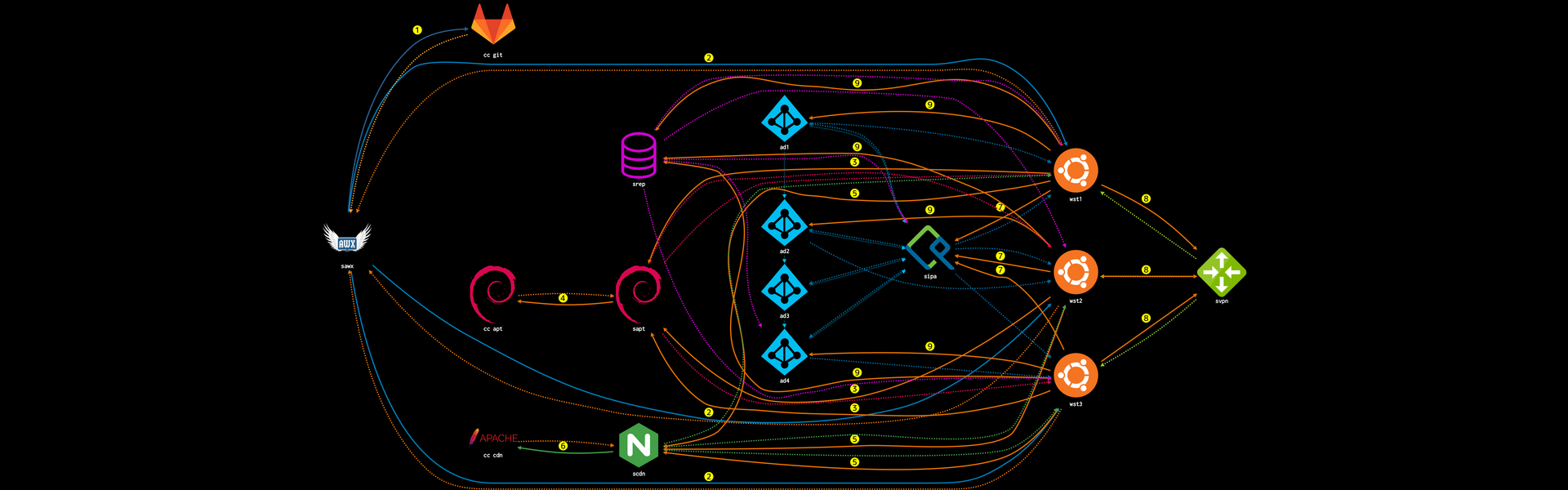
Well, then we were ready to deploy…
To do the deployment is to do the same thing but with many workstations at the same time, then basically it begins to become more complex, it is similar to the above, that is:
- AWX communicates with GitLab, gets the code and it will run a team, in this case 3 jobs these 3 jobs get the changes, but need local resources
- some local resources are the local APT cache a local CDN which is one nginxthat we have there in a VM in a server, but then it needs resources against the FileServer that is inside of the subsidiary
- and finally to be able to have a centralized login you need to talk to the IPA that is in Headquarters and also with the Cluster of the 4 ADs that are in Headquarters then there begins to be a lot of traffic from one side to the other, which is a little… colorinche, but hey, it works,
In real life, hardly anyone sees that all this is happening behind the scenes, inside AWX or they see green or they see red and everything went well or they call us.
stg staging
Well, next stage, we’re ready for staging !
Staging, basically… That is to say, go out to production in this case but with a single Subsidiary, instead of 300 to see if the solution works
And there we find things, right?
Well there are not only 3000 workstations, there are thousands of different peripherals!

(let’s see if I can pause, there)
In these peripherals we had to make the workstations that are all the same for a cashier position, also be for the manager or for the receptionist or for whoever is inside the Bank and has to work that same workstation with a Cash Scanner checks, with a ticket printer or whatever it takes…
The technology we use in summary is this:
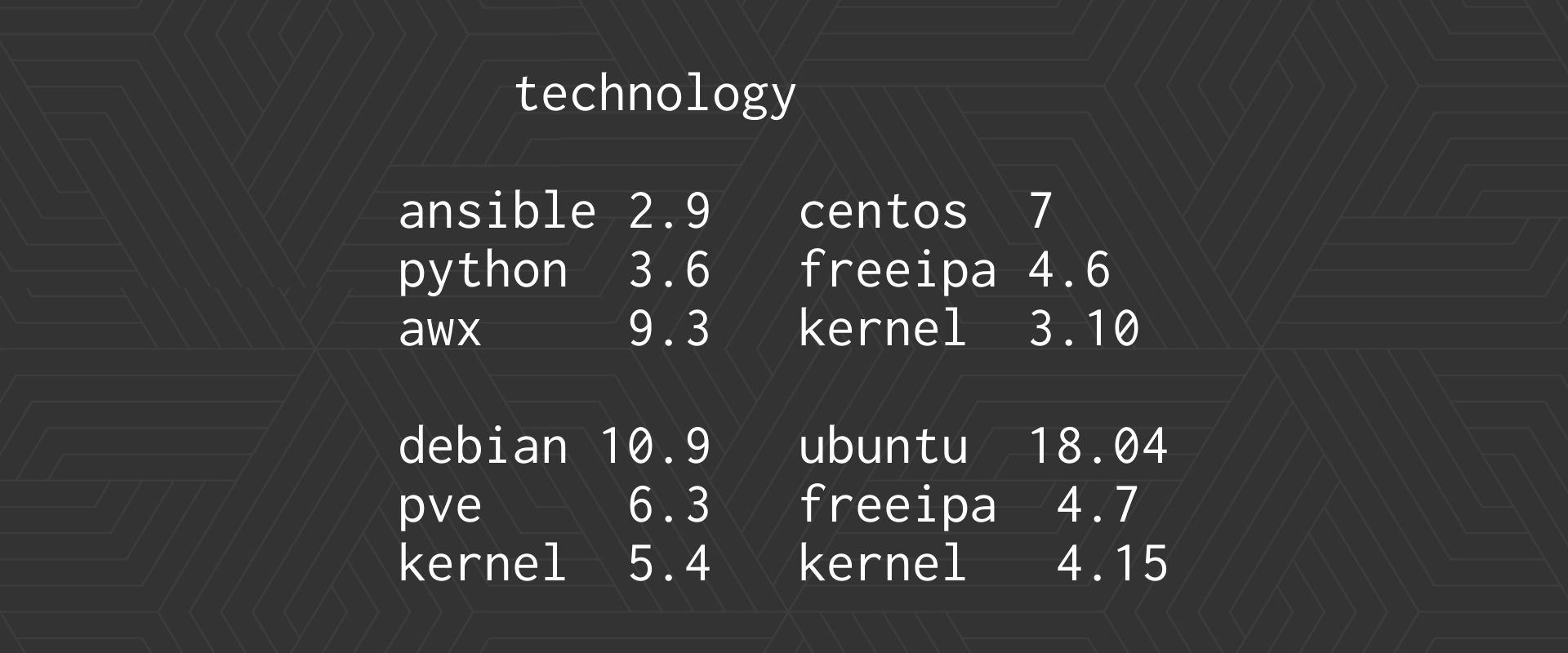
- Ansible, Python, AWX
- On the IPA side, IPA goes with CentOS, CentOS 7, when we started the project there was CentOS 7, not now, we are going to migrate it
- on the Debian 10 server side, when we started it was stable, Proxmox 6.3
- and the same on the side of jobs, we are already a little old…
Like any big migration project, when you finish migrating it, you have to start over!
The advantage is that it would only be to update some playbooks and roles, in short, we already have the deployment tool!
Well, we have 10 virtual machines, to recap, with different uses this… PrintServer, FileServer …

Within GitLab we have more than 200 repositories!

Here and there I pause, this was an important change of work, normally in a project no matter how big it is with 1, 2, 5 repositories…
And going to work with 200 repositories… it’s chaos!
It’s chaos and on top of that everything is versioned and many repos are nested that some depend on the others and well it’s possible! GitFlow helped a lot there.
And the important thing there is that there is 1 repository called
inventory which is the entire inventory of all the equipment that is
turning around, are versioned in one place and there is a repository
called awx, that is, all the information to run the /AWX/ deployment
, which could be done manually from the administration interface we did
it via code and then that code is shipped and deployed and versioned.
(well… And that’s where everything was hung… right? That’s the end of it!)
Well there AWX, the number of projects we have, more than 200 projects, 300 inventories, nothing, many templates, each one does something different

(Let’s see if… Pause)
Well, this is a summary of how we have come so far, that is, we had 6 months of laboratory, 1 year of development, 1 year of deployment of the solution, 87 days in staging, that is, we had a subsidiary for almost 3 months in operation running, fully migrated, server and new.
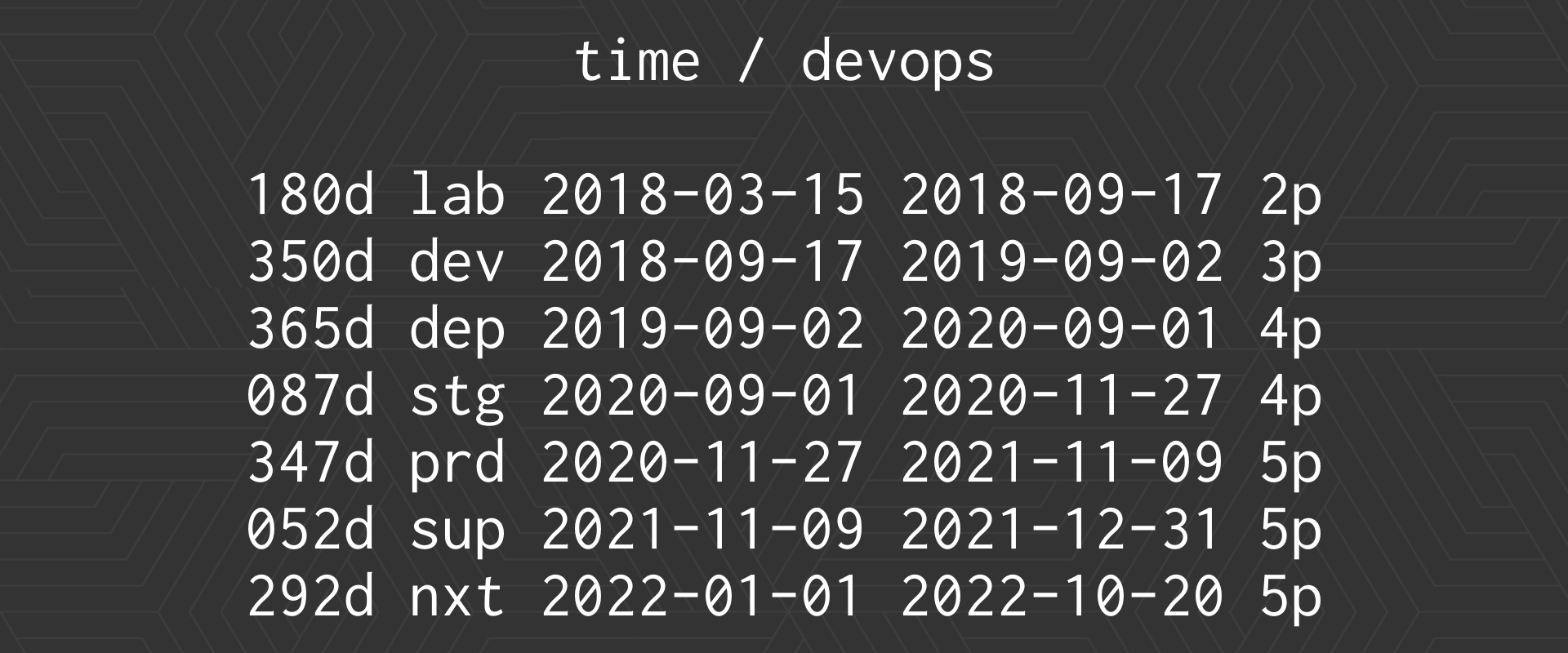
And from there began the arduous task that we got to here, let’s say we got there, we designed the solution, but the implementation was done by the Bank’s Implementations team, the truth is that they managed to do it in less than 1 year!, they came to migrate 3 per night! In 347 days, 300 subsidiaries migrated
And that is something important to understand, we are talking about a Bank and in a Bank that is how it closes at 06:00, opens at 09:00. Well, that was the window that the Implementations team had to change the server, change the rack, change the switches, rewire everything, install a new Operating System, deploy from Headquarters and in the morning everything continues to operate, like people go and do I don’t know their fixed term and everything works!
And it was obviously done in 2 stages, a first stage of servers and a
second stage of workstations, but initially, that is all the
Subsidiaries, went from one day to the next to throw away the
infrastructure they had and start up with a new one.
And something important is that, one difference that this project had, is that before the VPN was outside and in this case the server that replaced the infrastructure of the Subsidiary had the VPN inside the virtualized server, so it was quite a challenge that’s good and we finished in 2021, on September 9, the deployment of all the Subsidiaries was finished.
We entered there what would be support, which is really good as you know, support for something recently migrated is like finishing a little what we had been doing and from there well… Evolutionary maintenance so to speak, this there are improvements every day and new challenges and developments to fix.
(wait… nothing works for me)
prd production

Well let’s jump to Production We are in Production!
This is a way to see production!
(let’s see if we can increase)
This is an interpretation of what the migrated Bank is for us!
In the center of all that, this AWX, each balloon is a team that we can manage…
(let’s get closer!)
Come here in the center, this AWX which is a single team that is virtualized in Headquarters, which is going to connect for example here in red/orange Branch 105 and that Branch 105 well has its 10 virtual machines, its Proxmox server, its PrintServer and its 10 or 15 workstations there and the same is going to happen to 252 next to it, to 85 and to all the others!
It’s chaos!
I don’t know how they did this before! That we used AWX and had everything and Ansible versioned .
But the truth is that…
The only way to be able to manage so many computers on such a large
scale and know what is happening to each one and to see why it doesn’t
work, I don’t know, the printer of Subsidiary 24 , it’s like…
No hay otra manera, tiene que ser centralizado y tiene que estar automatizado!
sup support
(I don’t know how we got here on time? I have 3 minutes left!)
One of the little problems we had when we started Production was this!
That we did all the tests that we did of user login, although we simulated a certain load, we were never going to have the load that was production, which is basically around 10:00 in the morning, you have 2000 people who “log in” at the same time!
And then that good generated, a few seconds of delay for example there we are seeing that there is… More than 20 seconds of delay in the login is like a problem!.
So well, this is something that we mitigate in some way by generating a login cache synchronization and an API in the middle to just in time try to synchronize those users and well the definitive solution is going to come soon with a Cluster of IPAs in Instead of just one, we believe that it will be the solution, but well, it is one of the problems with the concurrence of many users at the same time.
(and I lost everything, wait, F5)
nxt next
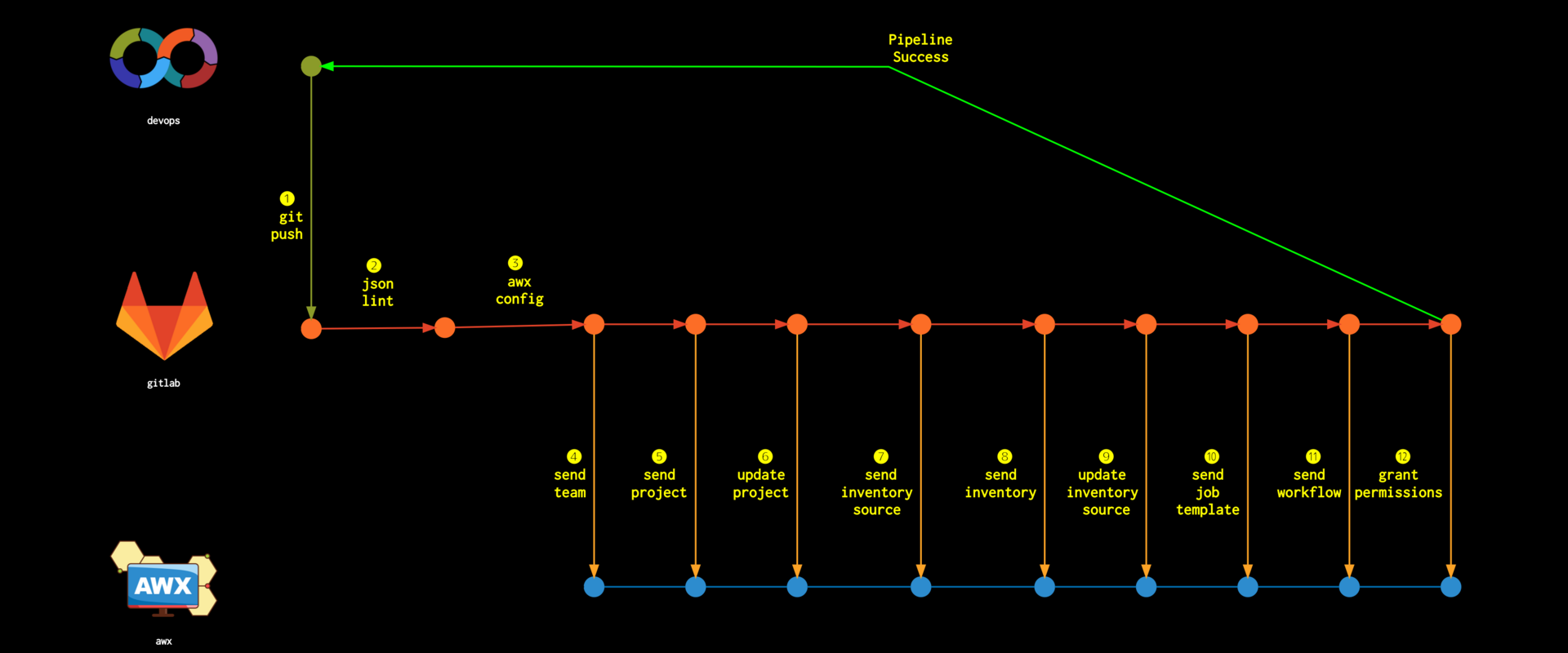
Well, what’s next?
We are working with many things in parallel but well here, this is a brief graphic that basically what we do is the AWX update solution , that is, at the beginning, what did we do?
We made a template in AWX, trial and error, trial and error until it worked for us and we said, well, this is it!
And now we have to pass it to production and pass it to Production, well, we exported a .jsonand that JSON we put it in production by hand, let’s say with commands from a CLI but basically manually and we said “that’s it!”
But hey, that’s not cool, that Development touches Production, so what we did is a script that what it does is, as soon as you start developing in a branch of your role or your playbook, as soon as you do push, GitLab deals with the CI to do whatever it takes to get that template deployed .
- it is first deployed in Development
- if it went well, the deploy in Development is deployed in Staging and if it turned out well in Staging, let’s say, it fulfilled the two steps and passed the entire test circuit, we generate a release
And we say to the Bank’s Technology team, “hey, you can deploy such a release” and the pass to Production uses the same script used by GitLab CI but triggered by a SysAdmin who says everything is going… (and who mistrusts us…! )
Well, that’s basically an idea and a summary of the migration project that we had to do from gcoop, I didn’t say it before but:
gcoop is a Free Software Cooperative, we work exclusively with Free
Software, we don't have bosses, we don't have employees, we are all
partners and it is another way of working and it is possible that we do
things like this, like these and that they work!
So as of now, I got right to 20 seconds! I answer questions, we have a few minutes, if you dare? I am still standing!
Questions?
Hello, how are you, good chat! Zarpado laburo… this one wanted to ask you how they did it, because I imagine that they must have had some exception, when they found in the middle of the night, this a server or a team that did not respond as it should…
They called me!
They called you! Guard every night! Year and peak?
No no, at the beginning, the truth is that the Implementation team there was a lot of people from the Bank’s side.
We only Design and Develop the solution, but this is operated by a very large team of our own and also outsourced, let’s say in some way, to be able to cover the entire country.
We are talking that you have a subsidiary in Salta, you have a subsidiary in Tierra del Fuego, Neuquén, wherever you can think of, then…
Well, I didn’t mention it, this was also in Pandemic, that is, we started in 2018 and the big migration process was from 2020-2021…
Eh, they were learning, basically at the beginning they needed us to be there accompanying the deploys, then they only called us when there was something strange, that is if that something strange could be solved in some way or automated so that it would not happen again, let’s say al otro día hacíamos una nueva plantilla, una nueva corrección y listo la próxima vez no volvía a pasaror they already knew how to mitigate it.
Perfect. Thank you!
(Any other questions? Here I go…)
They had to deal with, they had workstations that are laptops or basically how they dealt with intermittent that a laptop or a desktop computer could be turned off and Ansible, that is, it goes from the server talking to the nodes that it affects
Well, yes, the workstations are very tiny HP Pro Desktops, mini, beautiful, they start up in less than 30 seconds, they are operational, they have, I think, 8 GB of RAM, 256 SSSD, that is, they are strong machines…
We have a template that does a WakeOnLAN, basically on one or more computers, so let’s say, if necessary, first run that template and then run whatever you want. Always the execution of AWX what it executes and does not find turned on will tell you “I did not arrive, it does not know why” and you can tell it “I will execute again on those that did not arrive” There in the middle what you do is good, you generate another execution to say I turn on all the equipment .
Due to energy savings, they also told us at one point that it was convenient to turn off the equipment, so the equipment is also programmed to turn off at a certain time, so is there a time when you are obliged if you want to know if you reach everyone? You have to turn them on!
Then things also happen to you to say well, we did that every time a team obtains an IP, it goes to the inventory and is updated in case that team for some reason changed its Subsidiary, which could happen.
Eh also what we did is that this equipment notifies by SNMP its IP, its hostname and the last deploy it had and then later you can do sweeps by SNMP to say “well, let’s see what equipment is turned on and who are they?”
Obviously this as we were working we had to make different versions and there is always the dilemma that “do I have all the equipment in the same version?” well, you have to ask and redeploy !
Good afternoon, a question… As you said at the beginning, the teams lift the OS image from the server and install it on the workstation, let’s say, right? My question would be if you evaluated this possibility due to an inability of the server to set up virtual machines to deploy all the workstations required for a Bank or did you see any other advantage in this system? Thank you!
Eh no, part of it was trying to have a technology and an architecture that the Bank itself could respond to, that is, we couldn’t go out with a spaceship, let’s say, it had to be… There is a team for each person, it is a physical team and yes there is no connection to Headquarters or something is not working, that equipment has to at least be able to serve at least to say, I don’t know, open a spreadsheet and write NO SYSTEM and print it, let’s say at least for that, in that sense we also did virtualization with KVM, also for security reasons and it was much simpler in the operation of replacing equipment, that is = if in doubt if a piece of equipment does not work you throw it away and redeploy it and you do not have to think about what is happening to it = and they are all the same, that is, you can take a team from the front door and put it in the checkout line and it has to walk out, obviously it has all the services it needs for that, but it is the idea that they are all the same and nothing, let’s say strange, I don’t know if it answers the question…
…but before I forget…
Here I put, well our website is https://g.coop.ar/ it is the new domain that we now have in Argentina and part of the solution is there.
In GitLab 13 and GitHub 14, there are Ansible roles and playbooks that are available for you to use and improve:
- https://github.com/gcoop-libre/ansible-role-deploy-git-repos
- https://github.com/gcoop-libre/ansible-role-git-bare-repos
- https://github.com/gcoop-libre/ansible-role-pure-ftpd
- https://github.com/gcoop-libre/ansible_role_sssd_conf
- https://github.com/gcoop-libre/ansible_role_test_users
- https://github.com/gcoop-libre/ansible_sudoers
- https://gitlab.com/gcoop-libre/ansible_role_apt_pin
- https://gitlab.com/gcoop-libre/ansible_role_freeipa_sssd_tools
- https://gitlab.com/gcoop-libre/ansible_role_hp_linux_tools
- https://gitlab.com/gcoop-libre/ansible_tools
- https://gitlab.com/gcoop-libre/freeipa-sssd-tools
We made more than 200, of which more than 200, I don’t know, about 30
are not ours! That is, we take roles from the community, if someone
works in Ansible, Geerlingguy 15 is for example a good
base to start with and we extend them as needed and combine them with
our own roles!
(I have the microphone there…)
Good afternoon, the talk is very nice, I wanted to ask about the workstations, did you use the Ubuntu distribution, is it for any particular reason regarding Hardware characteristics or is it because of the user’s utility?
I like Debian, but the support you need for some applications, you will not find it up to date and we are a Development company that today we are 20 people and we were migrating 6300 computers and we said, well at some point this could scale and we can’t provide support, so we rely on large international Free Software development companies that can provide support if we can’t, then the best thing would be to work with a Debian -based distro that has some commercial support if necessary, which Same for server services.
(Here’s another question…)
Very good talk, two, a simple question that is to know what tool is this that makes the graphics? And the other question, a little more complex, no, eh well I have worked with Ansible and it is very good for provisioning servers and everything else, eh but I think that behind all this there is also a great network work so that the servers have access or the workstations have access to a certain server and I don’t know if there is a firewall involved or what? How do you handle all of that with Ansible as well ? Or good to do it manually I think it’s a lot, right? Or do you have any other solution?
Everything that is the new infrastructure, is made with Ansible as code, this not only allowed to simplify the deployment but also allows the Information Security Department and the Good Audit Department to check that it is installed, that is, there were specific requirements that we had to meet but which are specific firewall rules that are managed by another sector and as if, in order to be able to deploy, the rule must be in force, we do not manage it, we only ask for a JIRA so that it is working, let’s say, at the team level, whatever is necessary goes to run such a service and needs to reach such a destination.
And as for the tool, all the graphs that are in the presentation, even the timeline, are made with GraphVizbecause GraphViz basically allows you to code, that is, I didn’t make this drawing, I wrote code and that code became that drawing .
(Any more questions? Go ahead…)
Thank you… I wanted to know how all this originated? Why not… How was a requirement of the Bank? You sold it to him…?
gcoop … Eh… I’m 15 years 16 old in gcoop, I’ve been since 2007 a few months after it started, I’m not a founder, but I’m from the first litter let’s say…
And ever since we offered services and consultancy to the Bank, we
basically developed CRM, the critical mission system of Telephone
Contact Center and Associate Contact Management (Gestión de
Contactos del Asociado) 17 , that is, when you call by
phone, well, there is a CRM behind it that we developed from the start
of the cooperative, like this that has been running for 14 years and has
had many more migrations than this one, but well, without detracting
from it, it is a giant ABM but it has 5,000 users, so it is quite
critical.
This is how we have developed other projects, we had never done infrastructure until 2018, that is, it was the first time and they analyzed different offers and proposals and since they have a clear line of working with Free Software, they came to us and we spent 6 months convincing them to that it was possible and well we could do it and well we are improving it just like this, every day there is a new challenge.
We are, Thank you!
Closing
Thank you so much OSiRiS ! Well thank you very much!
Excellent talk! Great gcoop support Free Software and the development of that style, much more is needed!
I ask you to stay here while we close the next presentation that will be in English, so those who need it, behind us we have headsets for the real-time translation of our stars of the night, there in the booth, so good, many thanks again OSiRiS, a new round of applause, see you in a few minutes…
Questions
The event used the swapcard platform and after the talk I could see that they asked several questions, some were answered at the time, but others were pending, so I answer each question here.
Why install Debian and then PVE on top? Was it easier than directly installing PVE with its own image?
Mainly because in this way we could completely automate the installation, there are some configurations of the Operating System that must be done before installing Proxmox, for example the network configuration is quite complex, the servers have 10 network cards and we had to fix versions of packages in addition to registering the server in the AWX inventory .
how do playbooks log in to computers, do they use ssh key exchange? or what method?
Ansible is agentless and therefore AWX connects to computers using SSH keys, which are defined and configured in the PXE installation process /both for servers and /workstations .
what is that of gcoop could you develop it a little more the way it works?
gcoop is the Free Software Cooperative, it was born in 2007 and today it has 20 people organized horizontally and self-managed (that is, there are no bosses or employees ), it is a work cooperative and is dedicated to consulting and software development using exclusively Free Software MORE DATA on the gcoop.coop website.
What did you mean in the part about when they run the playbooks, “The important thing is the limit”?
When executing a playbook, it will be executed on all hosts in an inventory and for example the inventory wst( workstations ) has 3000 hosts, if you do not specify a limit, the default playbook will try to execute on all 3000 hosts in parallel and you will hardly want and/or you need to do it in as many teams at the same time, the most prudent thing is to establish a limit, for example by Subsidiary, although there are Subsidiaries with less than 10 teams, some have more than 60 teams, you can specify 1 or more hosts, filter examples:
| limit | definition |
|---|---|
| f0001 | all the teams in the groupf0001 |
| f0001:f0002 | all the teams in the groups f0001andf0002 |
| wst-8CC123:wst-8CC124 | only in teams wst-8CC123andwst-8CC124 |
| wst-8CC123 | only on the teamwst-8CC123 |
How did you deal with connection failures or timeouts that may arise?
Each Subsidiary has at least 2 links from different providers and throughout the country, there are different “bandwidths”, basically in each Subsidiary they began by deploying 2 computers in parallel and if there were no errors it was increased to 4 devices in parallel, and so on until finding the maximum number of devices in parallel without interruptions.
If a team’s deploy connection was broken, that team was then retried, and the playbook picked up where it left off (in effect, it rechecks each task and determines if it needs to be run again).
If they changed their IP, how were they updated later in the Inventory? Did they use an agent to inform the controller?/
We use a script in Network Manager Dispacher 18 that
calls updating the host, that is, the workstation modifies the AWX
inventory awx-cli every time it receives a new IP and if the host does
not exist in the inventory, it is created immediately.
Could someone tell me the name of the software they use to graph?
I made the graphs using GraphViz
You will surely be interested in reading…
ChangeLog
2022-11-13 20:39agregar y actualizar tags OpenGraph2022-10-28 14:13add links to in titles to Draft"How to migrate 6300 hosts to GNU/Linux using Ansible and AWX"2022-10-28 14:26use thumbnails form images in Draft"How to migrate 6300 hosts to GNU/Linux using Ansible and AWX"2022-10-28 14:18fix typo in footnote reference in Draft"How to migrate 6300 hosts to GNU/Linux using Ansible and AWX"2022-10-28 13:37add Draft"How to migrate 6300 hosts to GNU/Linux using Ansible and AWX"2022-10-28 13:26renombrar 2022-10-20-howto-migrate-6300-hosts-to-gnu-linux-using-ansible-and-awx.org a 2022-10-20-como-migrar-6300-equipos-a-gnu-linux-usando-ansible-y-awx2022-10-26 17:48agregarCómo migrar 6300 equipos a GNU/Linux usando Ansible y AWX